xyz@xyz-pc:~$ sudo iptables -A OUTPUT -p tcp --syn --dport 12345 -j DROP xyz@xyz-pc:~$ curl --connect-timeout 10 "http://192.168.1.110:12345" curl: (28) Connection timed out after 10001 milliseconds
读取数据超时
1 2 3
xyz@xyz-pc:~$ sudo iptables -A OUTPUT -p tcp -m state --state ESTABLISHED --dport 12345 -j DROP xyz@xyz-pc:~$ curl --connect-timeout 10 -m 20 "http://192.168.1.110:12345" curl: (28) Operation timed out after 20001 milliseconds with 0 bytes received
拒绝连接
1 2 3
xyz@xyz-pc:~$ sudo iptables -A OUTPUT -p tcp --dport 12345 -j REJECT xyz@xyz-pc:~$ curl --connect-timeout 10 -m 20 "http://192.168.1.110:12345" curl: (7) Failed to connect to 192.168.1.110 port 12345: 拒绝连接
xyz-macdeMacBook-Pro:dev-demo xyz$ python mixin_demo.py Init people. People can eat! People can drink! People can Traceback (most recent call last): File "mixin_demo.py", line 44, in <module> people = People() File "mixin_demo.py", line 39, in __init__ print "People can ", self.sleep() File "mixin_demo.py", line 30, in sleep raise NotImplementedError(u"can't sleep.") NotImplementedError: can't sleep.
objc[20307]: Class JavaLaunchHelper is implemented in both /Library/Java/JavaVirtualMachines/jdk1.8.0_131.jdk/Contents/Home/bin/java (0x1077344c0) and /Library/Java/JavaVirtualMachines/jdk1.8.0_131.jdk/Contents/Home/jre/lib/libinstrument.dylib (0x10874d4e0). One of the two will be used. Which one is undefined. Exception in thread "main" org.springframework.beans.factory.NoSuchBeanDefinitionException: No bean named 'teacher2' available at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBeanDefinition(DefaultListableBeanFactory.java:775) at org.springframework.beans.factory.support.AbstractBeanFactory.getMergedLocalBeanDefinition(AbstractBeanFactory.java:1221) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:294) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.support.CglibSubclassingInstantiationStrategy$LookupOverrideMethodInterceptor.intercept(CglibSubclassingInstantiationStrategy.java:290) at com.noogel.xyz.lookup.GetBeanTest$$EnhancerBySpringCGLIB$$e79f57a6.getBean(<generated>) at com.noogel.xyz.lookup.GetBeanTest.showMe(GetBeanTest.java:5) at LookupTestMain.main(LookupTestMain.java:9)
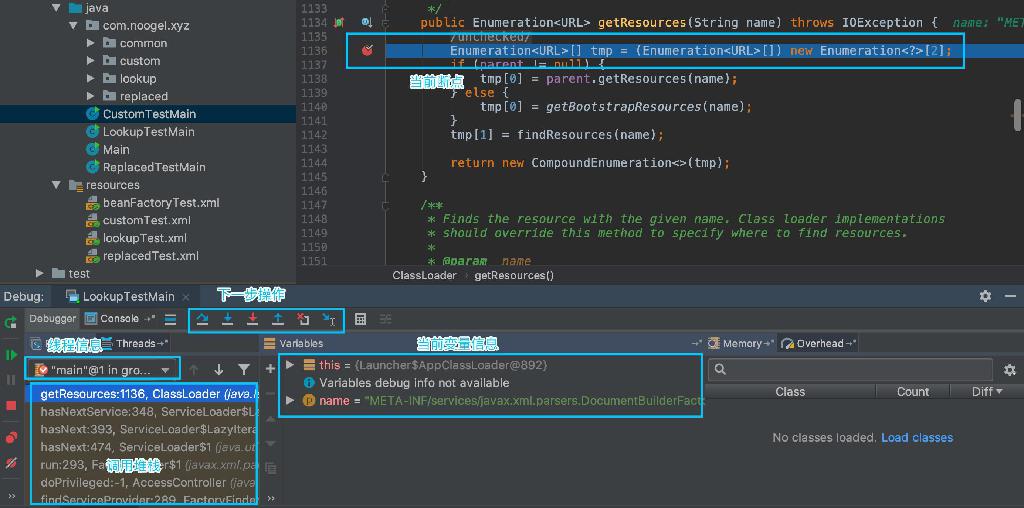
使用IDE断点调试
IDE 可以帮我们做很多事,大大提高了我们的开发效率,那么如何用好这样一个工具也是很关键的,这里说一下利用 IDE 进行 debug 调试。
学习一门编程语言肯定是用来解决实际问题或找一份工作的,那么你要知道并不仅仅是学习这门编程语言,而是整个技术栈。了解一个语言的技术栈可以去招聘网站上看,一般都会写至少需要精通一门编程语言,熟练使用 MySQL 解决并优化问题,熟练使用并了解各种 MQ 原理等等。那么这些都是需要去了解的,起初学习可以为了用而用的去实践一个更完整的需求。