Redis 数据结构
跳表(Skip List)
怎样理解跳表
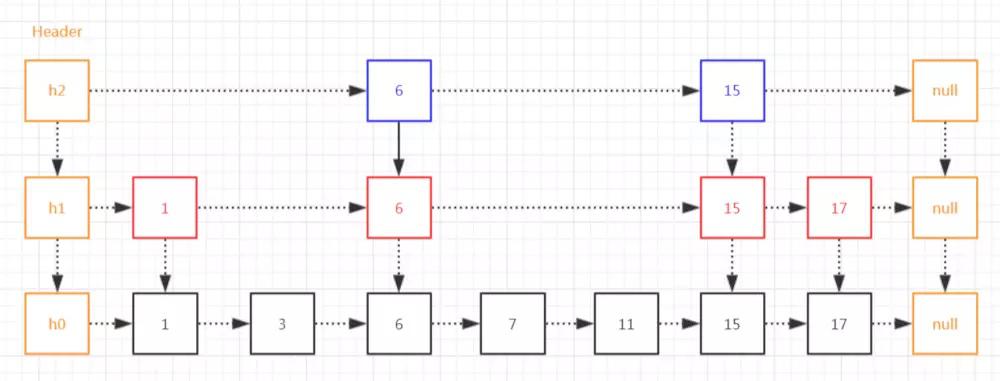
用一种比较通俗的方式去说,跳表是一种带有 N 级索引的有序链表,其中 N 级索引的作用是可以加速查找到链表的目标节点。
比较大众化的解释是,跳表是一个随机化的数据结构,实质就是一种可以进行『二分』查找的有序链表。这里对于随机化的理解是 N 级索引节点的选择上。
跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。在一定程度上可以代替红黑树(Red-black tree)。
跳表的结构

从链表说起,对于普通链表中,即使其存储的数据是有序的,当我们要寻找一个数据,时间复杂度也会比较高 O(n)。
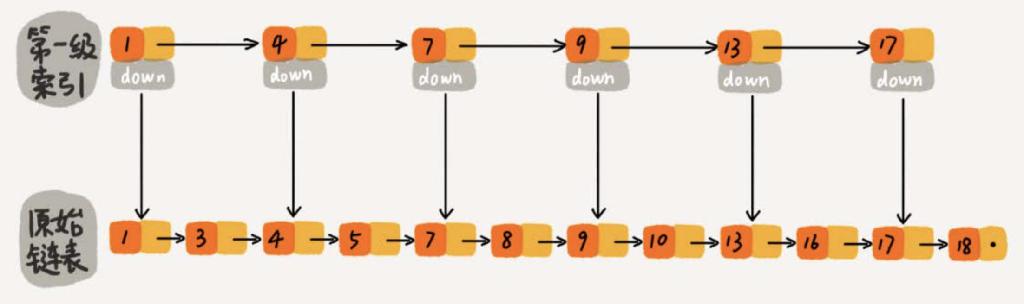
然后我们对链表建立一级索引,每两个节点提取一个节点放到索引层,其中的 down 指针指向下一级。
当我们寻找节点 16,只需要走过 1' -> 4' -> 7' -> 9' -> 13' -> 13 -> 16 节点即可(17'也要访问判断),而原始链表需要走过 10 个节点,节省了 2 个节点路径。如果我们再抽出二级索引后是这样子的。
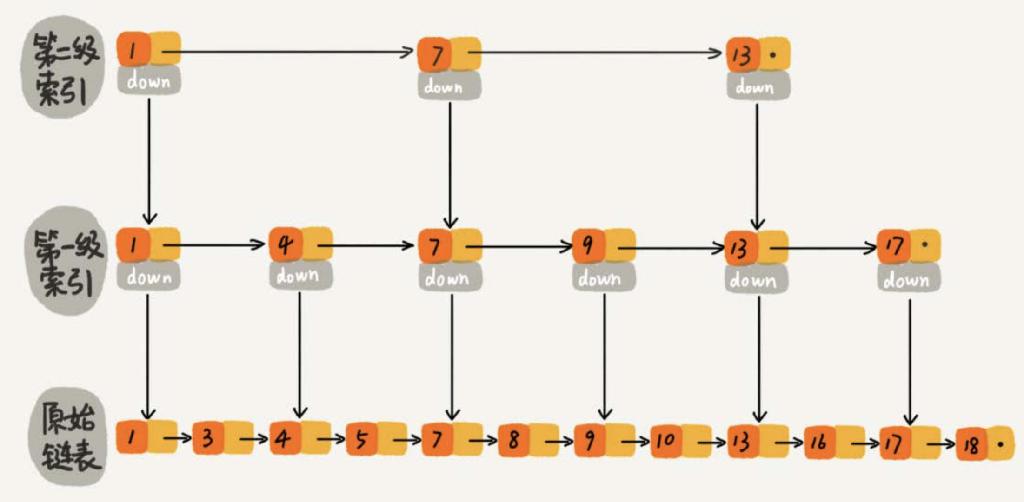
寻找节点 16 只需要走过 1'' -> 7'' -> 13'' -> 13' -> 13 -> 16 节点。这样我们又可以加快查找到目标节点,图中举例节点比较靠前,试想节点靠后,并且增加了 N 级索引之后效率一定会提升很多。
跳表的性能指标
单一链表的查询时间复杂度是 O(n),插入、删除的时间复杂度也是 O(n)。
以两个节点为跨度的话,那么跳表有如下总结:
- 第 k 级索引的节点个数是
n/(2^k) - 假设有 h 级索引,最高级索引有 2 个节点,高度
h=log2n - 1(2为底数),每一层都遍历 m 个节点,时间复杂度为 O(m*log n)。此时算得 m=3。
以多个节点为跨度,可以节省更多节点,是空间和时间上的相互折中。在实际开发中,索引节点只存储关键值和关键指针,之后链表节点才存储实际对象。
跳表的的查询、插入、更新、删除时间复杂度均为 O(log n)。
如何选择索引层?通过一个随机函数决定将节点插入到哪几级索引中,随机函数特点是要保证跳表索引大小和数据大小平衡性。
跳表在 Redis 中的应用
Redis 中有序集合通过散列表 + 跳表实现的,主要支持的功能有:
- 插入一个数据;
- 删除一个数据;
- 查找一个数据;
- 按照区间查找数据;
- 迭代输出有序序列;
相比红黑树,跳表在区间查找上有更好的性能;并且实现起来也相对容易;可以通过调整索引策略来平衡性能和内存使用;红黑树插入删除时为了平衡高度需要旋转附近节点,高并发时需要锁,跳表不需要考虑。
关于源码分析:https://segmentfault.com/a/1190000013418471
参考
https://www.jianshu.com/p/dd01e8dc4d1f
https://blog.csdn.net/pcwl1206/article/details/83512600
整数集合
在一个集合中只有为数不多的整数时,Redis 使用 intset 整数集合存储数据。具有如下特性:
1 | typedef struct intset { |
- 数据从小到大排序并且自动去重。
- 数据类型实际存储在 encoding 中。
- 当 encoding 中的数据类型不能满足时会自动进行类型升级。
- 重新分配空间
- 迁移
- 添加新元素
- 时间复杂度为 O(n)
- 不支持降级操作。
优点:
- 灵活,不用考虑整数集合类型,直接添加自动升级。
- 节省空间,只在必要时进行升级。
升级操作是指将整数由 16 位、32 位、64 位的方式增加支持范围。
IO 模型
通俗的理解 Redis 是一个单进程单线程模型的 KV 内存数据库,截止到目前官方会在年底发布多线程版本,并且 Redis 也有自己的持久化方案。采用 I/O 复用模型和非阻塞 IO 技术,被广泛应用在高并发场景中。
Redis 高性能的几个关键点:
- 完全基于内存操作,数据也是存储在内存中。
- 数据结构简单,很多查找和操作的时间复杂度在 O(1)。
- 单线程模式,避免了上下文的切换和锁竞争。
- 使用了 I/O 多路复用模型和非阻塞 IO。
Redis 同时支持多个客户端连接,采用 I/O 多路复用模型(select\poll\epoll)可以同时监听多个 IO 流事件。
多路指的是多个网络连接,复用指的是复用同一个线程。
采用多路IO复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
TODO I/O 多路复用