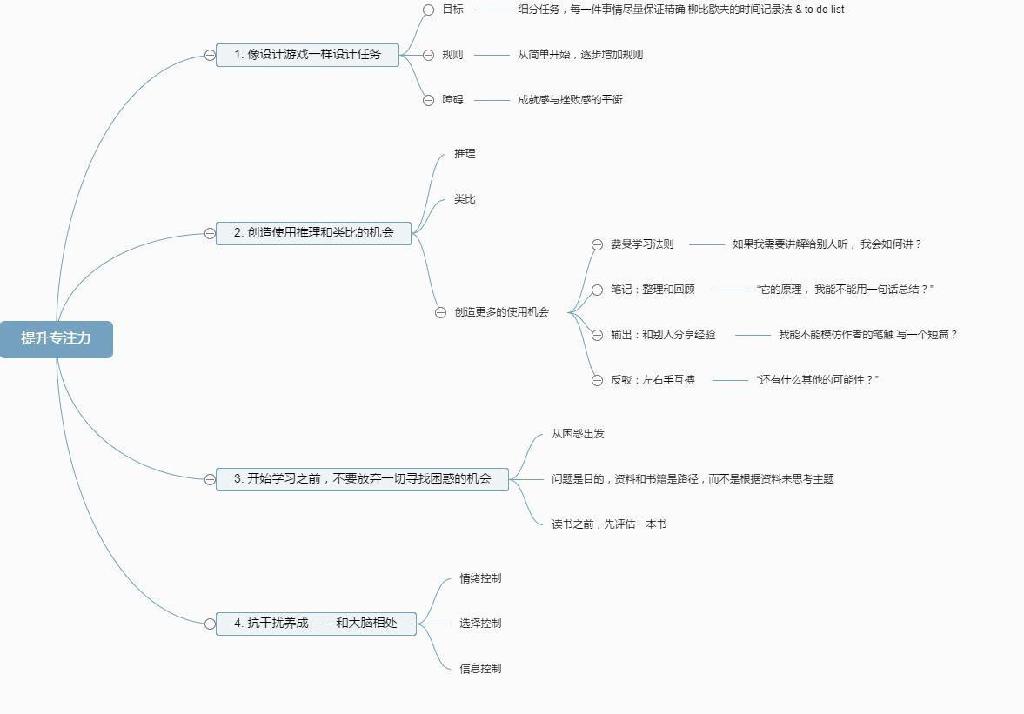
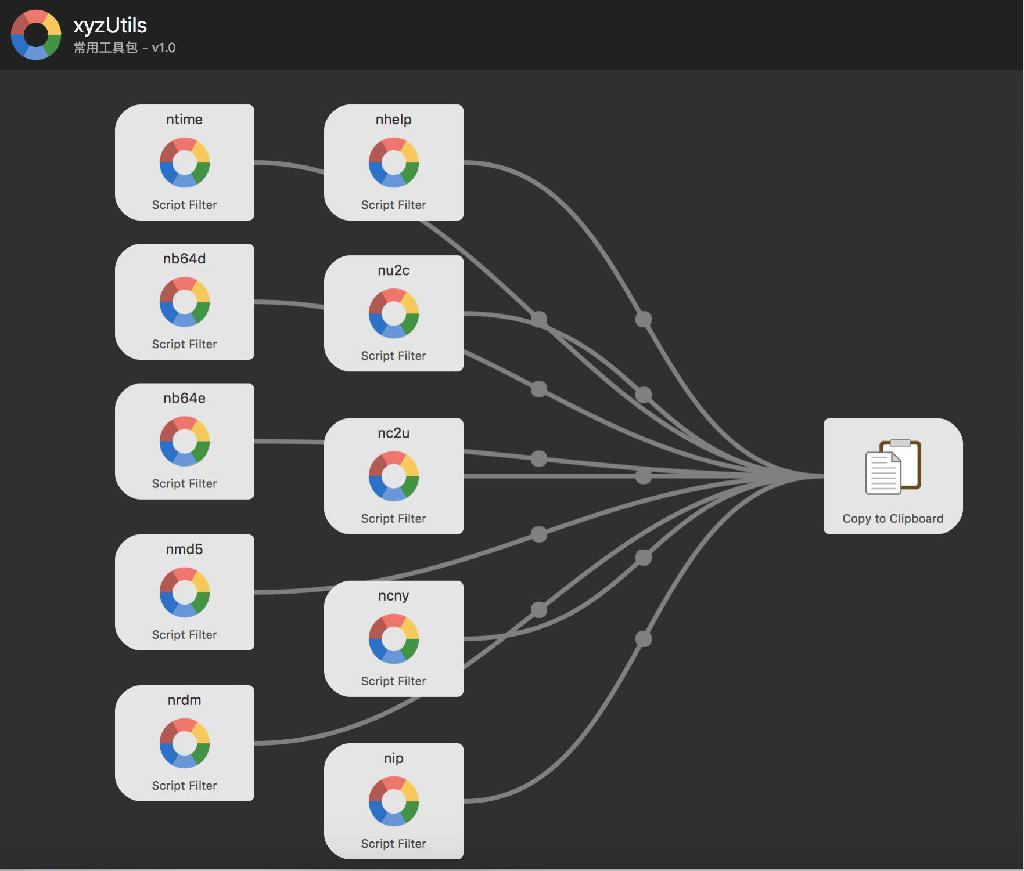
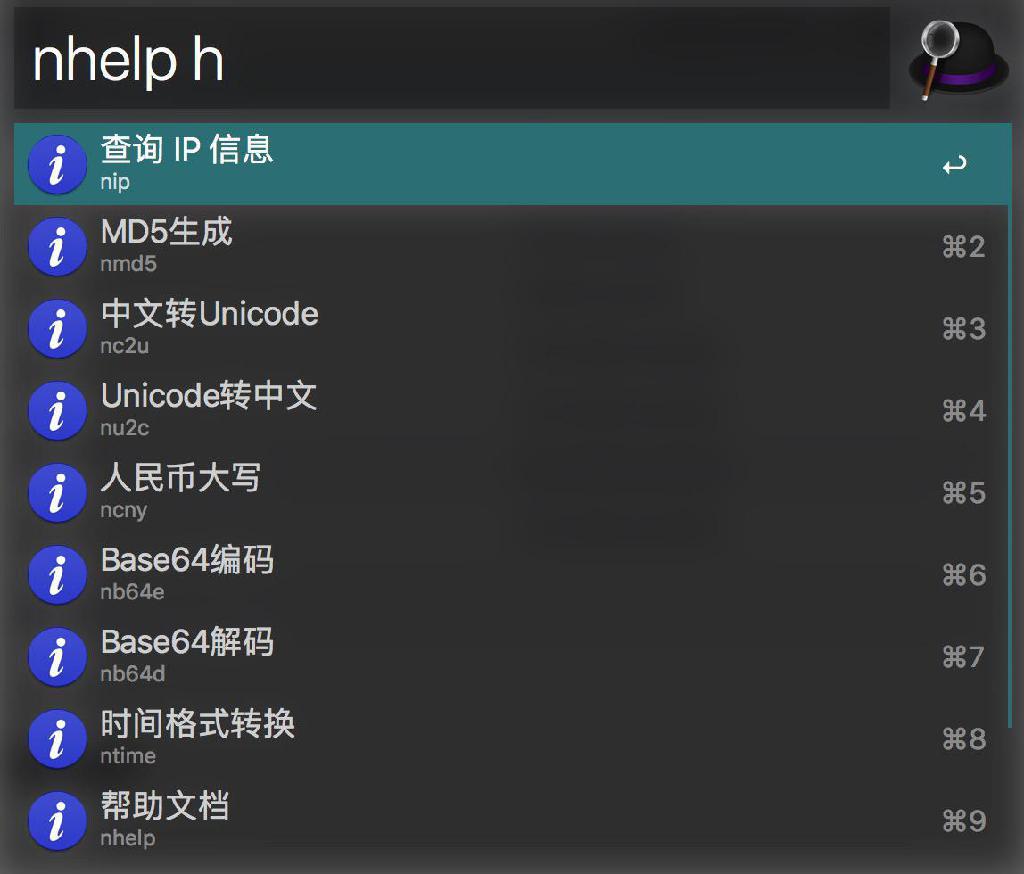
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
|
=====================================
2017-12-18 11:47:27 7fd5dd6f6700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 57 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 22630 srv_active, 0 srv_shutdown, 15047550 srv_idle
srv_master_thread log flush and writes: 15067795
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 21761
OS WAIT ARRAY INFO: signal count 42765
Mutex spin waits 38129, rounds 296291, OS waits 3638
RW-shared spins 25778, rounds 578697, OS waits 16634
RW-excl spins 4632, rounds 145148, OS waits 1184
Spin rounds per wait: 7.77 mutex, 22.45 RW-shared, 31.34 RW-excl
------------
TRANSACTIONS
------------
Trx id counter 167458
Purge done for trx's n:o < 167444 undo n:o < 0 state: running but idle
History list length 942
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0, not started
MySQL thread id 2700260, OS thread handle 0x7fd5dd6f6700, query id 16186792 10.21.0.2 wallet init
SHOW ENGINE INNODB STATUS
---TRANSACTION 167433, not started
MySQL thread id 2700100, OS thread handle 0x7fd5dd7fa700, query id 16185344 10.100.27.2 wallet cleaning up
---TRANSACTION 167449, not started
MySQL thread id 2700073, OS thread handle 0x7fd5e6581700, query id 16186116 10.100.53.2 wallet cleaning up
---TRANSACTION 167434, not started
MySQL thread id 2700060, OS thread handle 0x7fd5e6685700, query id 16185479 10.100.53.2 wallet cleaning up
---TRANSACTION 0, not started
MySQL thread id 2699993, OS thread handle 0x7fd5dd5f2700, query id 16184159 10.100.27.2 wallet cleaning up
---TRANSACTION 0, not started
MySQL thread id 2699968, OS thread handle 0x7fd5dd633700, query id 16183926 10.100.53.2 wallet cleaning up
---TRANSACTION 0, not started
MySQL thread id 2699967, OS thread handle 0x7fd5dd7b9700, query id 16183863 10.100.53.2 wallet cleaning up
---TRANSACTION 0, not started
MySQL thread id 2699966, OS thread handle 0x7fd5e6540700, query id 16183754 10.100.53.2 wallet cleaning up
---TRANSACTION 0, not started
MySQL thread id 2699965, OS thread handle 0x7fd5e4049700, query id 16183668 10.100.53.2 wallet cleaning up
---TRANSACTION 0, not started
MySQL thread id 2699964, OS thread handle 0x7fd5e66c6700, query id 16183581 10.100.53.2 wallet cleaning up
---TRANSACTION 0, not started
MySQL thread id 2699963, OS thread handle 0x7fd5dd6b5700, query id 16183494 10.100.53.2 wallet cleaning up
---TRANSACTION 167457, ACTIVE 11 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 360, 1 row lock(s), undo log entries 1
MySQL thread id 2700275, OS thread handle 0x7fd5dd737700, query id 16186778 10.21.0.2 wallet update
INSERT INTO `ttt` (`id`, `no`, `trade_number`)
VALUES
(586, '856195904590458889', '200526175912156728')
------- TRX HAS BEEN WAITING 11 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 50 page no 5 n bits 96 index `idx_number` of table `test`.`ttt` trx id 167457 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 14 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 29; hex 5a484c4956454255593230313730353236323233323432363434353939; asc ZHLIVEBUY20170526223242644599;;
1: len 8; hex 0000000000000229; asc );;
------------------
---TRANSACTION 167447, ACTIVE 602 sec
4 lock struct(s), heap size 1184, 3 row lock(s)
MySQL thread id 2699383, OS thread handle 0x7fd5e4251700, query id 16186751 10.21.0.2 wallet cleaning up
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: 0 [0, 0, 0, 0] , aio writes: 0 [0, 0, 0, 0] ,
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0
Pending flushes (fsync) log: 0; buffer pool: 0
6707 OS file reads, 383968 OS file writes, 119945 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.11 writes/s, 0.09 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 74, seg size 76, 733 merges
merged operations:
insert 34, delete mark 169019, delete 2
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 149489, node heap has 168 buffer(s)
0.00 hash searches/s, 0.05 non-hash searches/s
---
LOG
---
Log sequence number 394355624
Log flushed up to 394355624
Pages flushed up to 394355624
Last checkpoint at 394355624
0 pending log writes, 0 pending chkp writes
65750 log i/o's done, 0.04 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 77266944; in additional pool allocated 0
Dictionary memory allocated 669112
Buffer pool size 4607
Free buffers 1024
Database pages 3415
Old database pages 1240
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 11699, not young 475003
0.00 youngs/s, 0.00 non-youngs/s
Pages read 6606, created 13587, written 300725
0.00 reads/s, 0.00 creates/s, 0.05 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 3415, unzip_LRU len: 0
I/O sum[3]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Main thread process no. 12657, id 140556665968384, state: sleeping
Number of rows inserted 227014, updated 19739, deleted 89828, read 47831814
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
|