关于读写分离架构的思考
前言
分布式系统主要的目的之一就是解决大量用户的高并发问题。自己做过几个业务系统,也和别人聊过他们所做过的业务系统,其实大家都使用了相同的数据库,有的系统会使用 Redis 缓存,会使用 MQ 做系统解耦,有的也会使用搜索引擎。这些系统的构件相同的地方都是在处理数据,只不过职责不同罢了。归纳有以下几类:
- 数据库提供结构化的持久保证。
- 缓存为了提高并发和响应速度。
- MQ 带着事件消息将后续任务解耦。
- 搜索引擎提供快速的全文检索能力。
以上这几个构件就可以组成相对完备的实时数据系统,可以应对常见的业务需求。
数据框架
关于一个业务系统的通用数据框架可以用下面的图来表述。
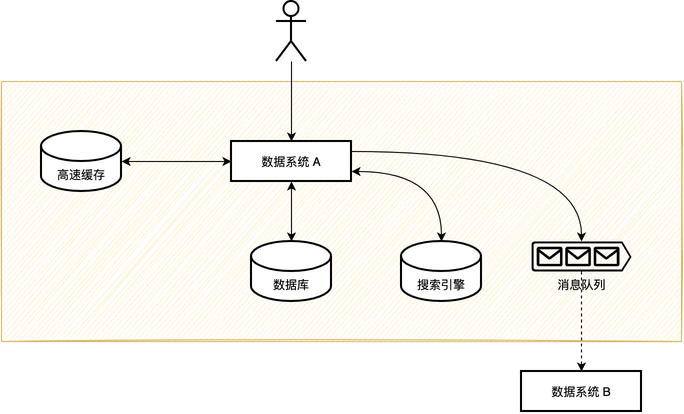
关于整个框架的运行方式可以简单的从读和写两个角度来看。
从写的角度来看,首先需要保证数据被正确处理和持久化,处理完主存数据,需要发送事件消息到 MQ,然后将数据同步到高速缓存和搜索引擎,整个流程是需要满足事务性。
从读的角度来看,需要面临的主要问题是和主存的一致性问题,一般保证弱一致性即可。读数据的简化流程是先读缓存,读不到读数据库,再回填缓存。
适用场景
而各式各样业务功能和逻辑对数据的处理都归为两种操作——读和写,只是不同的系统侧重点不同,主要分为以下几类:
- 『读多写少』的系统
- 百度搜索
- 电商商品搜索
- 『写多读少』的系统
- 广告计费系统
- 双十一的支付系统
- 『读多写多』的系统
- 电商秒杀
- 新浪微博
处理思路
高并发读
首先说说『读多』的解决方案,最常见的是用户到服务器之间的多级缓存策略(也许描述的不够准确,可以继续往下看),从服务端到用户逐层递进有以下几种:
- 分布式缓存
- 内存缓存
- CDN 缓存
- 客户端缓存
从上到下,缓存越接近用户对服务器的压力约小,访问速度越快,弊端是一致性的处理越不可控,机器成本和问题排查成本越高。
从数据变化角度来看可以分为动态内容和静态内容,动态内容可以根据业务需要采用分布式缓存和内存缓存的方式,可以通过设置过期时间来自动刷新。静态内容可以通过 CDN 和客户端缓存的方式,一般是一些图片、HTML、CSS、JS 文件。
缓存的更新方式可以分为推和拉两种形式。缓存常见的三个问题略过。
第二种策略是串行读改并行,对于用户的一个请求,如果需要三个外部依赖,耗时分别是 T1\T2\T3。如果是串行化调用总耗时是 T1+T2+T3,在三者没有耦合关系的情况下,改成异步执行的总耗时为 Max(T1, T2, T3)。
第三种策略是批量请求,通过缓存或存储提供的批量命令,可以将单次读写请求改为批量请求,可以减少网络传输的总耗时。
高并发写
对于『写多』的解决方案,最常见的解决思路是对于数据分片,比如现实世界的高速多车道,医院的多诊室,以此来提升整体的吞吐量。在服务端比较常见的是数据库层面的分库分表,通过合理的分片算法,将数据尽量均匀的分散在不同的库表,通过分库可以利用起多台机器的资源。
除此之外,数据分片的设计策略还在其它方面有所体现:
- Kafka 的多个 Partition 的设计。
- ConcurrentHashMap 中 HashEntry 和 Segment 设计。
第二种策略是任务分片,将一个大任务拆分成若干子任务执行。你可能会立刻想到 CPU 的指令流水线,一条指令分为取指、译码、执行、访存、写回五个阶段,单条指令占用 5 个时间周期,每增加一条指令整体只需要再增加 1 个时间周期。
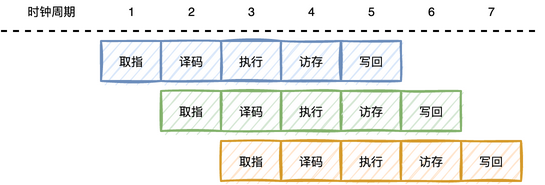
这些策略使用的就是分治思想,耳熟能详的就是 Map/Reduce 了,在 Java 中 ForkJoinPool 也是利用这一思想设计。
分治从字面上也很容易理解,分、治其实还有个合并的过程:
- 分(Divide):递归解决较小的问题(到终止层或者可以解决的时候停下)。
- 治(Conquer):递归求解,如果问题够小直接求解。
- 合并(Combine):将子问题的解合并得到父类问题解。
第三种策略是队列缓冲,如果请求量超过系统最大负载,可以放到 MQ 异步化处理请求,这时需要客户端支持异步结果响应。秒杀场景就可以将瞬时大量用户请求放到消息中间件,由服务端慢慢消费,再异步通知用户。
第四种策略是批量写。
读写分离
根据数据的访问特点,上面提到的各种策略本质上是读写分离,是微服务架构中提到的 CQRS。关于读写分离模式一般具有以下特征:
- 读和写设计的数据结构不同,为系统的读和写分别设计两个视图,设计适合高并发场景的数据结构和模型。
- 写数据通过数据库的分库分表来提高并发能力,然后异步写入缓存来提高读并发能力。通过异步写入搜索引擎来实现全文搜索。
- 因为缓存和搜索引擎是异步写入的,所以读到变更后的数据会有一定延迟,保障最终一致性,而非强一致性。
总结
回到最上面总结的数据框架,实现一个高并发系统所需的主要数据构件有缓存、数据库、搜索引擎、消息队列,以读和写两个视角将用户的大量请求分流到不同地方处理,然后通过多副本的方式对数据构件水平扩容,这本身也是一种分治思想。