高并发系统:读写分离架构的思考
分布式系统,如同现代信息世界的钢筋水泥,其存在的首要目的,就是驯服数据洪流,解决那令人望而生畏的“高并发”难题。
回顾这些年,我参与和观察过形形色色的业务系统:从早年的电商,到后来的社交网络,再到广告计费。虽然业务逻辑千差万别,但当你剥开那层层叠叠的业务代码,会发现它们在“数据处理”这件事上,使用的竟是几乎相同的积木块。
这让我意识到,构建高性能系统的关键,并不在于你选择了哪种炫酷的编程语言,而在于你如何理解和组织这些数据处理的“基石”。
这些基石,职责不同,但都围绕着“数据”运转。我将它们归纳为四类,它们构成了我们应对高并发挑战的实时数据系统。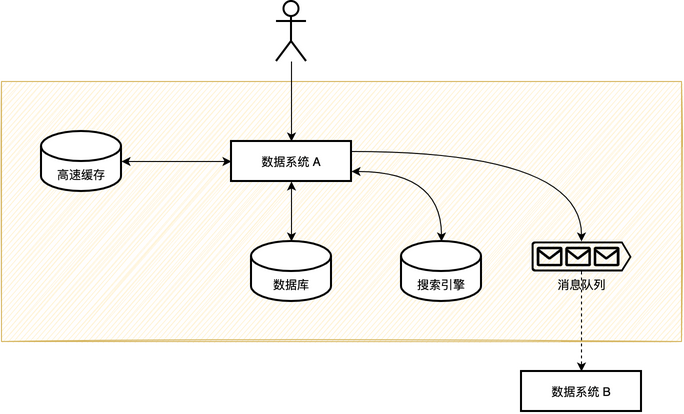
一、实时数据系统的“四件套”
想象一下一个高耸入云的摩天大楼,它的结构是稳定且分层的。我们的数据系统也是如此。
1. 数据库(The Anchor):结构化与持久的承诺
数据库是数据系统的“主存”,是所有数据的最终归宿。它提供结构化的保证,最重要的是,它承诺了持久化(Persistence)。无论发生什么,只要数据写入成功,它就在那里。
但我们都知道,数据库(尤其是关系型数据库)在面对极高并发的读写时,会成为瓶颈。这也是为什么我们需要其他构件来分担它的压力。
2. 缓存(The Accelerator):速度与并发的利器
缓存(如 Redis、Memcached)的使命非常单纯:提高并发能力和响应速度。它通常驻留在内存中,以极快的速度响应用户的请求。
它好比数据库前面的一个“快速通道”或“临时接待区”。绝大多数的读请求,如果能在缓存层面就被消化掉,那么数据库就可以高枕无忧。它是解决“读多”问题的首要武器。
3. 消息队列(The Decoupler):事件驱动与系统解耦
消息队列(MQ,如 Kafka、RabbitMQ)扮演着“邮递员”的角色。它的主要价值在于系统解耦和流量削峰。
当主系统完成核心写操作后,它不是同步地去更新缓存、通知其他系统,而是发送一个“事件消息”给 MQ。后续的任务(比如发送邮件、更新积分、同步到搜索引擎等)可以异步、独立地消费这些消息。这使得整个系统流程不再是僵硬的串行,而是灵活的事件驱动。
4. 搜索引擎(The Retriever):全文检索与高效查询
对于需要进行复杂、快速的全文检索(如商品搜索、站内搜索)的场景,数据库往往力不从心。
搜索引擎(如 Elasticsearch、Solr)的出现,就是为了提供快速的全文检索能力。它通过构建倒排索引(Inverted Index)等机制,让用户可以在数亿条数据中,以毫秒级的速度找到他们想要的内容。
这四件套——数据库、缓存、MQ、搜索引擎——构成了相对完备的实时数据系统。它们各自承担着不同的职责,共同处理数据的流入与流出。
二、数据流的“阴”与“阳”:读写分离的哲学
理解这套框架的运行,需要从两个截然不同的角度来看待数据流:写入(Write)和读取(Read)。
1. 数据的“写入”哲学:事务与最终一致性
目标:保证数据被正确处理和持久化。
一次完整的写操作,其核心流程必须满足事务性:
- 持久化主存数据: 数据首先要被写入到数据库,这是所有后续操作的基础和保障。
- 发送事件消息: 数据库写入成功后,系统需要立刻发送一个事件消息到 MQ。
- 异步同步: 监听 MQ 的服务,会将数据异步同步到高速缓存和搜索引擎。
这里的关键在于事务性。通常,我们会保证数据库写入和发送 MQ 消息在一个事务内完成(或者通过 TCC、本地消息表等方式保证最终的一致性),确保主存数据和“事件”的同步性。至于缓存和搜索引擎,它们通过异步机制最终与主存数据保持一致,这是一种经典的 最终一致性(Eventual Consistency) 模型。
2. 数据的“读取”哲学:一致性与性能的权衡
目标:在满足一致性要求的前提下,最大化响应速度。
在读数据时,我们面临的主要问题就是一致性。读到的数据,是最新写入的吗?
在高并发场景下,为了性能,我们通常选择弱一致性(Weak Consistency)或最终一致性。这意味着用户在写操作完成后,短时间内可能会读到旧数据。
读数据的简化流程是:
先读缓存 $\rightarrow$ 读不到读数据库 $\rightarrow$ 再回填缓存。
如果缓存命中,请求直接返回,速度极快。如果未命中,请求穿透到数据库,此时数据库的压力依然存在,因此需要有一套针对读请求的优化策略。
三、高并发的“分治”之道:读多与写多的处理
不同的业务系统,其数据访问模式截然不同。无非是两种操作的组合:读(Read)和写(Write)。
| 系统类型 | 读写特征 | 典型案例 | 核心挑战 |
|---|---|---|---|
| 读多写少 | 读操作远超写操作 | 百度搜索、电商商品搜索 | 响应速度和系统稳定性 |
| 写多读少 | 写操作是主要负载 | 广告计费系统、双十一支付 | 吞吐量和数据准确性 |
| 读多写多 | 读写压力都很大 | 电商秒杀、新浪微博 | 极端高并发下的系统均衡 |
针对不同的挑战,我们的处理思路都围绕着一个核心思想展开:分治(Divide and Conquer)。
1. 驯服“读多”:高并发读的层次策略
“读多”的解决方案,本质上就是一套多级缓存策略,将数据尽量推近用户。
| 缓存层次 | 距离用户 | 职责与特点 |
|---|---|---|
| 客户端缓存 | 最近 | 浏览器缓存、App 缓存。速度最快,但一致性最难控制。 |
| CDN 缓存 | 靠近 | 缓存静态文件(图片、JS、CSS)。全球分布式,极大地分摊服务器压力。 |
| 分布式缓存 | 适中 | 如 Redis 集群。服务端的共享高速缓存。 |
| 内存缓存 | 最远 | 应用进程内的缓存。访问速度最快,但容量有限。 |
缓存越接近用户,对服务器的压力就越小,访问速度越快。但弊端是一致性的处理越不可控,排查成本也越高。
除了多级缓存,还有两种重要的优化思想:
- 串行改并行: 将一个依赖多个外部服务的用户请求,从串行调用(总耗时 $T_1 + T_2 + T_3$)改为异步并行执行(总耗时 $\text{Max}(T_1, T_2, T_3)$)。这是通过多线程、协程或异步编程来实现的。
- 批量请求: 将多次单个请求合并为一次批量请求(例如 Redis 的 $MGET$ 或数据库的批量插入)。这可以显著减少网络传输的总耗时。
2. 驯服“写多”:高并发写的拆解策略
“写多”的解决方案,核心思路是数据分片,以提高整体的吞吐量。
最常见的是数据库层面的分库分表(Sharding),通过合理的分片算法(如按用户ID取模),将数据均匀地分散到多台机器上。这利用了多台机器的计算和存储资源,将“单车道”变成了“高速多车道”。
这种分片思想,在现代系统设计中无处不在:
- Kafka 的 Partition 设计: 将一个 Topic 的消息分为多个 Partition,每个 Partition 独立写,实现高吞吐。
- ConcurrentHashMap 的设计: 早期通过 Segment 锁,将大哈希表拆分为多个小片段,减少锁的竞争。
- 任务分片(流水线): 将一个大任务拆分成若干子任务,串行流程并行化。如同 CPU 的指令流水线,通过“取指 $\rightarrow$ 译码 $\rightarrow$ 执行 $\rightarrow$ 访存 $\rightarrow$ 写回”的阶段划分,实现了指令的并行处理,大幅提升了整体效率。
队列缓冲是另一个驯服写多的重要手段。如果瞬时请求量超过系统最大负载(如秒杀场景),我们可以将请求放入 MQ 进行异步化处理,由服务端慢慢消费,异步通知用户结果。这实现了流量削峰。
四、终极奥义:读写分离与 CQRS
上述所有策略,其本质都是在贯彻一个理念:读写分离(Read-Write Separation)。这在微服务架构中被称为 CQRS(Command Query Responsibility Segregation,命令查询职责分离)。
CQRS 的核心特征是:
- 设计分离: 为系统的“读”和“写”分别设计两个视图。读视图的设计目标是高并发、快速查询;写视图的设计目标是保证事务、数据完整性。
- 数据流分离: 写操作(Command)通过分库分表提高并发能力。写完成后,数据通过 MQ 异步地流入读数据存储:写入缓存提高读并发,写入搜索引擎实现全文检索。
- 一致性折衷: 读数据存储(缓存、搜索引擎)是异步写入的。因此,读到的数据会有一定延迟,我们保障最终一致性,而不是昂贵的强一致性(Strong Consistency)。
总结
回到我们最初的数据框架图。一个高并发系统,不过是利用数据库、缓存、搜索引擎、消息队列这四大构件,以读和写两个视角将用户的海量请求分流到最合适的地方处理。
通过水平扩容(Horizontal Scaling),利用多副本、分库分表等方式将数据构件进行拆分和复制,这本身就是分治思想在系统架构上的实践。
高性能的架构,就是数据流的艺术。它不是要追求某种极致的技术,而是在性能、一致性、可用性之间,找到一个适合当前业务的、精妙的平衡点。而这个平衡点,就隐藏在对这“四件套”的深刻理解和灵活运用之中。