畅文全索:文档检索系统的探索与实践
在日常的信息处理中,有效管理和查找文档是许多人面临的实际需求。无论是个人积累的资料,还是团队共享的文档,一个可靠的检索工具都能提供帮助。本文将介绍 畅文全索(xyz-search),一个基于 Spring Boot 和 ElasticSearch 开发的文档检索系统,旨在为用户提供一种相对便捷的文档内容查找方案。
💡 项目概述:畅文全索的功能定位
畅文全索被定位为一个辅助性的全文检索系统。它基于 Spring Boot 和 ElasticSearch 构建,尝试支持多种文件格式的全文内容检索。通过整合 Spring AI 功能,系统也具备了初步的智能搜索和内容分析能力,以期为用户提供更精准的检索体验。
本系统适用于个人文档管理或小型数字文档集合的检索场景,可处理一定规模的文档数据。它旨在为用户提供一个可行的文档检索和管理工具。
你可以在 GitHub 上找到畅文全索的开源代码。
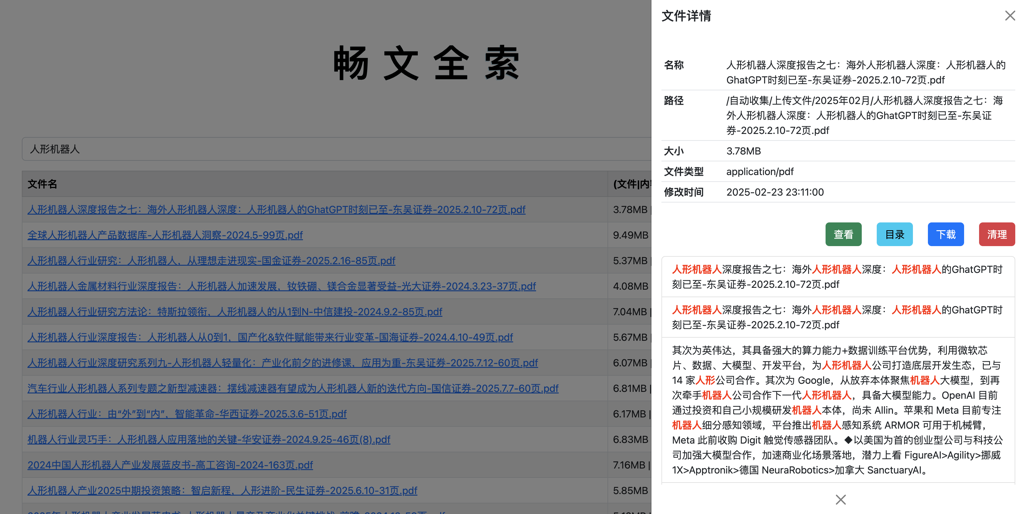
✨ 主要功能:畅文全索的特点
畅文全索在功能设计上,尝试涵盖了文档检索的一些核心需求:
📄 多种文档格式支持
系统在文档兼容性方面进行了一些尝试,目前支持多种常见文档格式的解析和索引:
- 办公文档:PDF、Word (docx)、Excel (xlsx)、PowerPoint
- 电子书:EPUB (支持内容解析与索引)
- 图像识别:通过集成 PaddleOCR,可提取图片中的文本信息。
- 多媒体:支持部分视频元数据索引。
- 网页与文本:支持 HTML 和纯文本文件 (TXT, MD, JSON 等)。
🔎 基础检索能力
畅文全索的检索功能基于 ElasticSearch,提供了一些常用的搜索特性:
- 全文索引:采用 ElasticSearch 作为底层索引技术。
- 中文分词:支持中文文本的分词处理。
- 索引更新:具备基本的实时索引更新机制。
- 属性过滤:支持文件属性的过滤检索。
- 结果高亮:对搜索结果中的关键词进行高亮显示。
🤖 AI 功能的引入
系统引入了 AI 相关功能,尝试提升检索的智能化程度:
- Spring AI 集成:利用 Spring AI 框架进行功能扩展。
- 语言模型辅助:尝试基于大语言模型进行内容理解。
- 对话式检索:支持初步的自然语言对话式检索模式。
- Ollama 模型支持:可配置本地部署 Ollama 模型。
📚 电子书管理辅助
对于电子书爱好者,系统也提供了一些辅助管理功能:
- OPDS 协议支持:兼容 OPDS 电子书协议。
- EPUB 阅读:内置简易的在线 EPUB 阅读器。
💻 界面设计与操作
系统提供了基本的 Web 界面,以方便用户操作:
- Web 界面:提供一个简洁的 Web 交互界面。
- 文档上传:支持文件上传功能。
- 文件采集:可设置自动采集指定目录下的文件。
- 移动端适配:界面设计考虑了响应式布局。
系统以 Spring Boot 作为主要开发框架,提供了 Web 界面和各类 API 接口。内部功能模块包括搜索、索引、AI 和文件服务。数据存储方面,主要依赖 ElasticSearch 进行全文索引,SQLite 用于系统配置数据,而 AI 功能则通过 Spring AI 实现。文件存储则独立进行管理。
🚀 部署指引:如何启动畅文全索
以下是使用 Docker 快速启动畅文全索的基本步骤:
通过预构建 Docker 镜像启动:
拉取镜像:
1
docker pull noogel/xyz-search:latest
运行容器:
1
2
3
4docker run -d --name xyzSearch --network xyz-bridge-net -p 8081:8081 \
-v /path/to/searchData:/usr/share/xyz-search/data \
-v /path/to/share:/data/share \
noogel/xyz-search:latest请将示例路径
/path/to/searchData和/path/to/share替换为实际的文件存储位置。
系统默认配置如下:
- 管理员账号:
xyz - 初始密码:
search - 访问地址:http://localhost:8081
注意:系统初始密码可在配置页面修改。当前版本账号不支持修改。建议在较为受控的网络环境中使用。
🔧 配置说明:定制化选项
系统启动后,用户可在 Web 界面进行必要的参数调整:
- 索引目录:指定需要进行索引的文档主目录,并可设置排除的子目录。
- 文件自动采集:配置监控源目录、目标存储目录、文件类型过滤规则以及是否自动删除源文件。
- OPDS 服务根目录:建议配置为 Calibre 库目录。
- 文件存储路径:包括手动上传和标记删除文件的存储路径。
- 通知邮件配置:用于系统访问通知的邮件设置。
- OCR 服务:配置 PaddleOCR 服务地址。
- 外部搜索链接:自定义文档详情页的外部搜索链接,如豆瓣、京东、谷歌。
- AI 对话检索:配置 AI 功能的启用状态,以及 Ollama、Elasticsearch 和 Qdrant 等相关服务的参数。
🐳 Docker Compose 部署:集成服务
对于偏好使用 Docker Compose 的用户,我们也提供了相应的配置,可以方便地部署包含 Elasticsearch、Qdrant 等服务的完整环境:
创建一个 docker-compose.yml 文件,并添加以下内容:
1 | version: '3' |
在 docker-compose.yml 所在目录执行:
1 | docker-compose up -d |
这将启动畅文全索服务。如需部署完整的服务栈(包含 Elasticsearch、Qdrant 和 PaddleOCR),请参考项目仓库中的详细 docker-compose.yml 配置。
📊 开发计划与贡献
畅文全索仍在持续改进中。目前已完成的功能包括 RAG 检索增强模型优化和中文分词准确率改进。未来的开发计划包括:
- 全新的响应式搜索界面
- 多用户系统支持
- 支持更多文档格式
我们欢迎对本项目感兴趣的开发者参与贡献,无论是功能开发、文档完善、Bug 修复,还是性能优化建议,都将为项目的进步提供帮助。
📄 许可证
本项目遵循 GNU General Public License v3.0 许可证。
希望以上内容能为您提供关于畅文全索的基本信息。如果您有进一步的疑问或建议,欢迎交流。