正则表达式 Cheatsheet
用来匹配和处理文本的字符串。 基本用途是查找和替换。一种不完备的程序设计语言。
锚点
^ 字符串开头,或多行模式中的行开头\A 字符串的开始$ 字符串结尾,或多行模式中的行尾\Z 字符串结束\b 字边界\B 不是单词边界\< 词的开头\> 词尾
字符集
\c 控制字符\s 任何一个空白字符([\f\n\r\t\v])\S 任何一个非空白字符([^\f\n\r\t\v])\d 任何一个数字字符\D 任何一个非数字字符\w 任何一个字母数字字符或下划线字符([a-zA-Z0-9_])\W 任何一个非字母数字或非下划线字符([^a-zA-Z0-9_])\x 十六进制数字\O 八进制数
量词
+ 1 个或更多* 0 个或更多? 0 个或 1 个{} 匹配指定个数{3} 精确的 3 个{3,} 3 个或更多{3,5} 3,4,5
添加 ? 表示非贪婪模式,懒惰型匹配,匹配最小子集。
1 | +? |
断言
?= 前瞻断言?! 负前瞻?<= 后向断言?!= or ?<! 负面回顾?> 一次性子表达式?() 条件 [if then]?()| 条件 [if then else]?# 评论
转移
\ 转义后面的字符\Q Begin literal sequence\E End literal sequence
『转义』是一种处理正则表达式中具有特殊含义的字符的方式,而不是特殊字符。
常用元字符
^[.${*(\+)|?<>
特殊字符
\n 新行\r 回车\t 制表符\v 垂直制表符\f Form feed\xxx 八进制字符 xxx\xhh 十六进制字符 hh
组合范围
. 除换行符 (\n) 以外的任何字符(a|b) a 或 b(...) 组(?:...) 被动(非捕获)组[abc] 范围 a b c[^abc] not (a or b or c)[a-q] 从 a 到 q 的小写字母[A-Q] 从 A 到 Q 的大写字母[0-7] 从 0 到 7 的数字\x 组/子模式编号『x』
范围包括在内。
例子
回溯引用
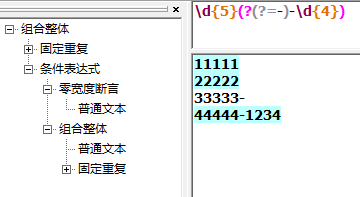
下面例子匹配 空格 字符 空格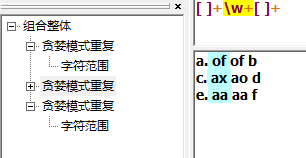
下面的例子使回溯引用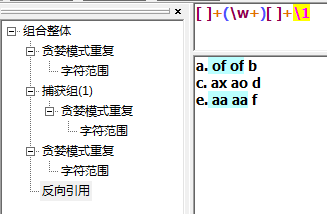
解释回溯引用,\1用来获取(\w+)中的字符串。第一个匹配上的of被\1引用,就变成表达式[ ]+(\w+)[ ]+of。
其中\1代表模式里的第一个子表达式,\2就会代表着第二个子表达式,以此递推。
替换
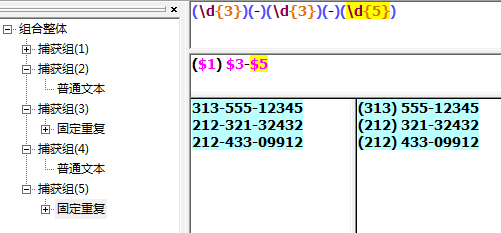
大小写转换测试工具不支持,待测试
向前查找、向后查找
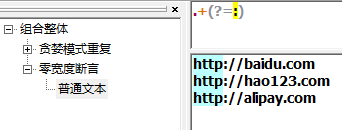
必须要放到一个字表达式中,如下例子,根据:来匹配,但是不消费他。(?=) 向前查找
(?<=) 向后查找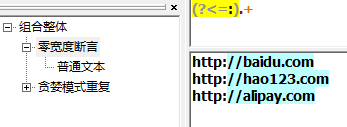
(?!) 负向前查找(?<!) 负向后查找
嵌入条件
(?(brackreference)true-regex)其中?表明这是一个条件,括号里的brackreference是一个回溯引用,true-regex是一个只在backreference存在时才会被执行的子表达式。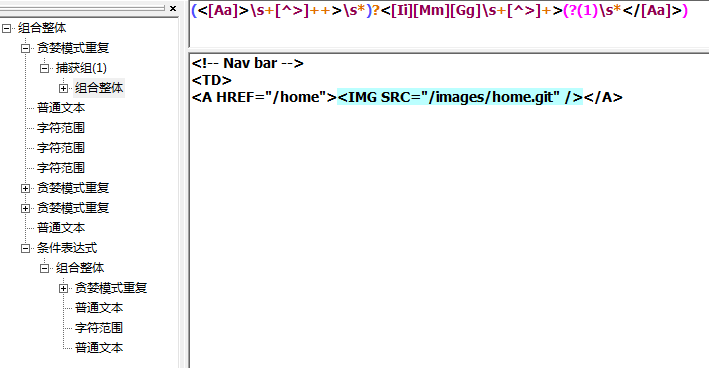
不区分大小写匹配
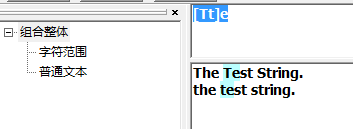
字符区间匹配
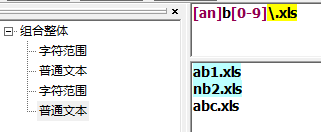
取非匹配
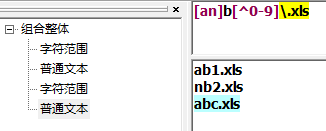
匹配多个字符
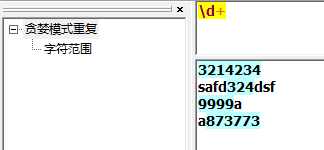
子表达式
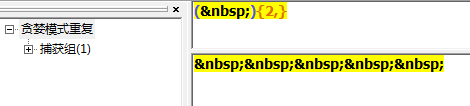
匹配四位数的年份
嵌入查找、向后查找组合应用